sunの呪縛のヘッダー
Sunの呪縛
πの計算
| 計算・テキストとか丸や四角の塗りつぶし等のBenchmarkを探したが見つけられなかった。 |
例えばWindowsで同じ処理を多重で行うと速度が半分とか4分の1に成ったんだけど
Sparcで行うと4個くらいまでならほとんど速度が落ちないCISCとRISCの差なのか
それをやったのはClassicの頃なんだけどね、40MHzとペンティアム200MHzの頃?
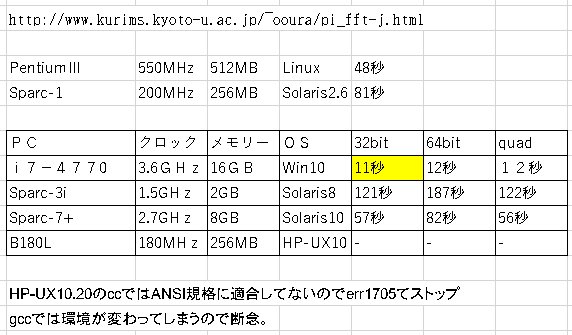
| 有名と言えばπの計算(ちょっと古いけど)。 |
詳しいことは分からないけどPI_CS.EXEってファイル。
参考データのSparc1の200MHzで81秒だから2.7GHzなら5秒台?WWW。
しかし残念な結果・・・・・
。
| 添付のバイナリーが最適化されてるんでしょ!!!。 |
64bitとquadをコンパイルしてガッカリ・・・・・・
一応32bitも実施。
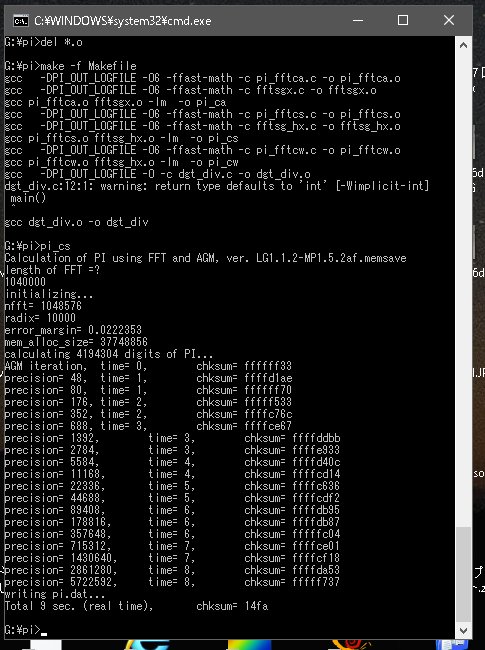
9秒ですか?・・・・・・・・・・・・。
コンパイラーの差なのか?
super-piを見ると。
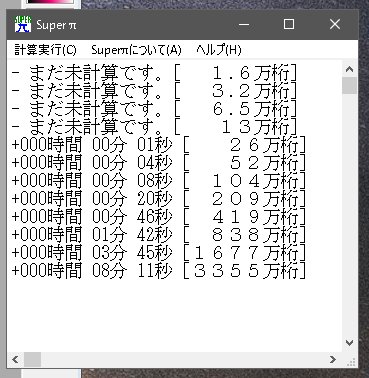
8秒で早いじゃん!
1000万だと9分で3倍以上遅い・・・・
同時だと流石4core8スレッド、ほとんど変わらない(1割ほど遅い)
8スレッドだから9個同時だと倍くらい遅い
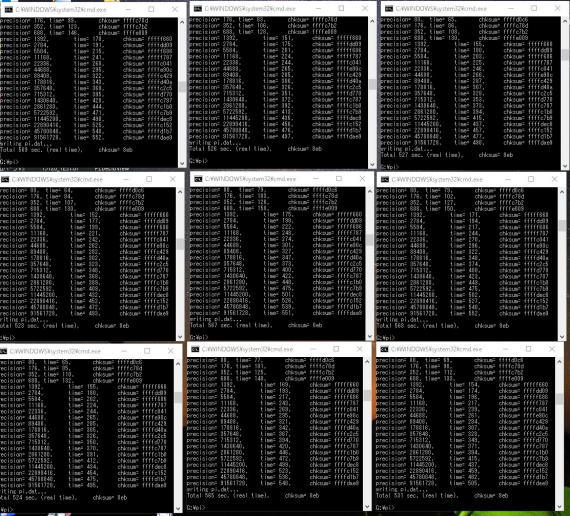
Sparcの8スレッドだと
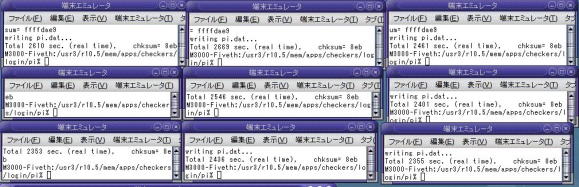
41分・・・・ほとんど縮まってない><
100スレッド同時起動なら勝てると信じよう・・・・・
もうガッカリです・・・・・・・・。
流石にwindow100個は開けないのでpi_cs.cを少し手直し
−−−−−−−−−−−−−−−−−−−−−−−−−−
/* scanf("%lg", &x);
*/
x = 1040000.0;
−−−−−−−−−−−−−−−−−−−−−−−−−−
入力を104万に固定
−−−−−−−−−−−−−−−−−−−−−−−−
f_log = fopen("pi_000.log", "a");
fprintf(f_log, "Total %.0f sec. (real time),\tchksum= %x\n", difftime(t_2, t_1), (int) sum);
fclose(f_log);
−−−−−−−−−−−−−−−−−−−−−−−−
を最後に追加して時間だけ書き出し。
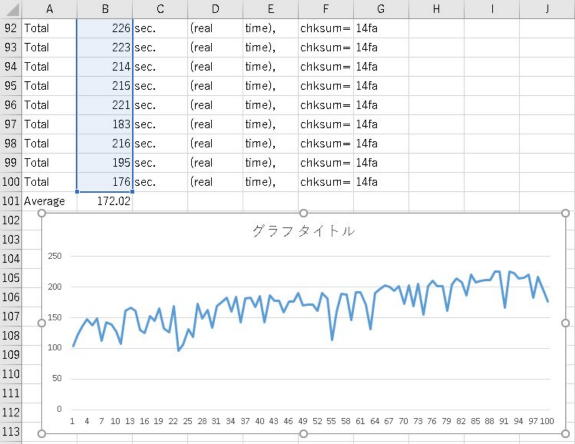
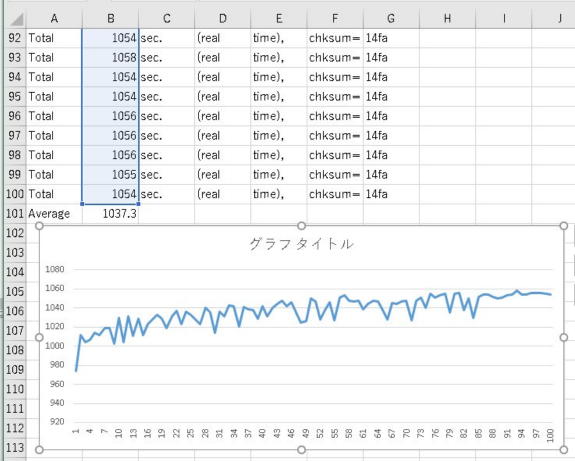
1=9:57=6.3倍
9=550:2450=4.4倍
100=1037:172=6.0倍
最後の望みとしてスワップが発生しているかもしれない。
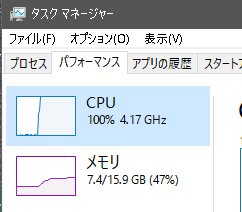
Windows10は100個のpi_csを起動するとマウスが固まるけど、
Solaris10は普通に使える所は評価したい><
gccは、Windowsが5.2.0でSolarisが2.95.2、あまり関係ないと思うけど。